Comment installer hadoop et spark sur windows 10?
Pour installer Hadoop et Spark sur Windows 10, suivez les étapes suivantes :
- Vérifier la version de Windows 10: Commencez par vous assurer que la dernière version de Windows 10 est installée sur votre système.
- Installer Hadoop et Spark: Téléchargez et installez la distribution Hadoop et Spark qui correspond à vos besoins. Apache Hadoop et Apache Spark sont des choix populaires. Visitez leurs sites officiels respectifs pour télécharger les paquets d'installation.
- Configuration de l'environnement:
- Installation de Java: Hadoop et Spark nécessitent l'installation de Java. Téléchargez et installez la dernière version du kit de développement Java (JDK) à partir du site web d'Oracle.
- Configuration de Hadoop: Accédez aux fichiers de configuration « core-site.xml » et « hdfs-site.xml » dans le répertoire d'installation de Hadoop. Configurez les paramètres tels que 'fs.defaultFS' et 'dfs.replication' en fonction de votre environnement.
- Configuration de Spark: Dans le répertoire d'installation de Spark, localisez le fichier 'spark-env.cmd' pour configurer les variables d'environnement telles que 'SPARK_HOME' et 'HADOOP_HOME'.
- Création d'un compte utilisateur:
- Compte d'utilisateur local: Créez un compte utilisateur local sur votre système Windows 10. Assurez-vous que l'utilisateur dispose des privilèges appropriés pour l'installation et la configuration.
- Création d'un mot de passe: Définissez un mot de passe fort pour le compte utilisateur nouvellement créé.
- Accéder à l'installateur Hadoop et Spark:
- Téléchargement de l'installateur: Téléchargez les fichiers exécutables de l'installateur Hadoop et Spark à partir des sites web respectifs.
- Processus d'installation: Double-cliquez sur les fichiers d'installation et suivez les instructions à l'écran. Au cours de l'installation, vous devrez peut-être spécifier des chemins d'installation, des répertoires et d'autres paramètres.
- Configuration et tests:
- Configuration de Hadoop: Configurer 'hadoop-env.cmd' pour définir les chemins Java et d'autres variables d'environnement.
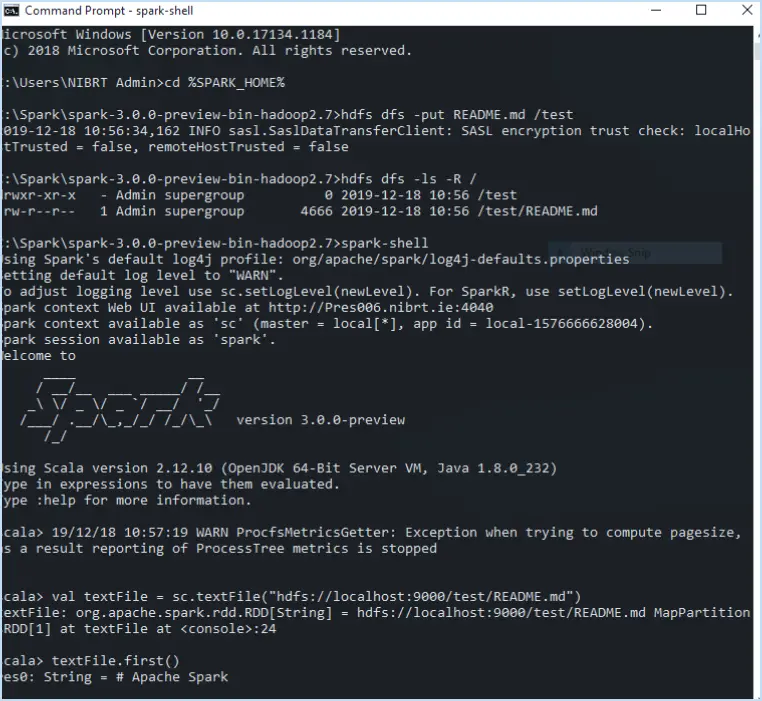
- Démarrer Hadoop: Lancez les services Hadoop à l'aide de 'start-all.cmd' dans le répertoire 'sbin'. Accédez à l'interface web Hadoop à l'adresse 'http://localhost:50070'.
- Configuration de Spark: Définissez 'spark-defaults.conf' pour affiner les paramètres de Spark.
- Exécuter Spark: Exécuter les applications Spark en utilisant 'spark-submit.cmd'. Surveillez la progression et les journaux pour une exécution réussie.
N'oubliez pas que la configuration d'Hadoop et de Spark sur Windows 10 implique plusieurs étapes complexes. Soyez attentif aux détails et veillez à suivre la documentation officielle fournie par les communautés Hadoop et Spark pour le dépannage et la personnalisation.
Apache Spark peut-il fonctionner sous Windows 10?
Oui, Apache Spark peut en effet fonctionner sur Windows 10. Cette bibliothèque logicielle open-source, développée à l'origine par Google et largement adoptée dans des plateformes telles que les moteurs de recherche et YouTube, a été conçue pour être compatible avec Windows 10. La dernière version d'Apache Spark a spécifiquement inclus la prise en charge de la plateforme Microsoft Windows. Cette avancée offre une opportunité précieuse aux scientifiques et professionnels des données d'exploiter les capacités d'Apache Spark directement dans leur environnement Windows 10, facilitant ainsi l'analyse efficace des données et les tâches d'apprentissage automatique. En conséquence, Apache Spark constitue un outil puissant pour les scientifiques des données qui cherchent à améliorer leur travail sur le système d'exploitation Windows 10.
Dois-je télécharger Hadoop pour Spark?
Si Spark est votre principal entrepôt de données, télécharger et installer Hadoop peuvent s'avérer nécessaires. Petites entreprises ou startups peuvent ne pas avoir besoin d'Hadoop. Hadoop, une plateforme open-source pour la gestion de vastes ensembles de données, prend en charge Spark. Si vous connaissez déjà Hadoop, il n'est peut-être pas nécessaire de le télécharger pour Spark. En revanche, si vous ne connaissez pas les deux, voici ce qu'il faut prendre en compte :
- Intégration: Hadoop et Spark peuvent fonctionner ensemble, améliorant ainsi les capacités de traitement des données.
- Complexité: L'installation d'Hadoop implique une configuration qui peut être décourageante pour les nouveaux venus.
- Évolutivité: Hadoop prend en charge le stockage distribué, ce qui est essentiel pour traiter des ensembles de données volumineux.
- Courbe d'apprentissage: La maîtrise des deux outils nécessite du temps et des efforts.
Évaluez vos besoins et votre degré de familiarité pour décider si Hadoop est nécessaire pour Spark.
Quelles sont les 5 étapes pour installer Hadoop?
Pour installer Hadoop, il faut suivre les 5 étapes suivantes :
- Conditions préalables : Assurez-vous que Java est installé et correctement configuré sur votre système.
- Téléchargez Hadoop : Obtenez la distribution Hadoop qui correspond à vos besoins sur le site officiel.
- Configuration : Modifiez les paramètres de base dans les fichiers de configuration, en spécifiant les chemins d'accès et l'allocation des ressources.
- Configuration SSH : Générez des clés SSH et configurez-les pour permettre la communication entre les nœuds.
- Démarrer Hadoop : Exécuter les commandes nécessaires pour lancer les services Hadoop.
L'installation d'Hadoop ouvre les portes à la manipulation efficace de grands ensembles de données.
Qu'est-ce qui est le plus rapide : Spark ou Hadoop?
Les vitesse entre Spark et Hadoop est la suivante subjective et dépend de vos besoins. Pour un rapide et fiable de données rapide et fiable, Spark présente un avantage. Cependant, lorsqu'il s'agit de trouver le meilleur pipeline de données performance de Hadoop, Spark pourrait s'avérer supérieur.
Hadoop a-t-il besoin de JDK?
Oui, Hadoop nécessite un JDK (Java Development Kit) pour fonctionner pleinement. Bien qu'il ne soit pas obligatoire, le JDK permet aux programmes d'interagir avec les fichiers Hadoop par le biais d'opérations de lecture et d'écriture. Bien que Java ne soit pas nécessairement natif sur toutes les plateformes, les experts s'accordent à dire qu'un JDK améliore les capacités d'Hadoop. Certaines préoccupations existent en raison du statut non natif de Java, mais sans un JDK, la fonctionnalité prévue d'Hadoop pourrait être compromise.
PySpark et Spark sont-ils identiques?
PySpark et Spark partagent le même objectif fondamental de permettre le développement d'applications big data. Cependant, ils présentent des caractéristiques distinctes qui les différencient :
- Le langage : PySpark est l'API Python pour Apache Spark, permettant aux développeurs d'utiliser Python pour la programmation Spark.
- Facilité d'utilisation : PySpark offre une expérience plus conviviale pour les amateurs de Python, tandis que Spark nécessite une expertise en Scala ou en Java.
- Performance : Native Spark (Scala/Java) pourrait donner de meilleures performances en raison de sa compilation directe en bytecode Java.
- Intégration : PySpark s'intègre de manière transparente aux bibliothèques Python, améliorant ainsi les capacités d'analyse des données.
- Communauté : Les deux ont des communautés solides, mais PySpark attire les développeurs centrés sur Python, alors que l'écosystème de Spark est plus large.
En résumé, PySpark est la version de Spark compatible avec Python, offrant une facilité d'utilisation et d'intégration avec Python, tandis que Spark est la bibliothèque de base nécessitant une expertise en Scala ou Java.
PySpark est-il suffisant pour le big data?
PySpark, une version du langage basée sur Python, est bien adaptée aux domaines suivants big data. Enraciné dans Python, il simplifie le traitement des grands ensembles de données. Son interface ressemble à Java et à R, ce qui permet de créer des applications Spark très performantes. Par essence, PySpark gère habilement des ensembles de données considérables et se targue d'une forte compatibilité inter-langues. Selon les experts, cela fait de PySpark une excellente option pour la construction d'applications de données volumineuses.